ELK初体验
近期遇到有分日志数据需要分析,计算部分不算复杂,直接shell脚本跑一遍大致也可以完成,但是其数据维度较多,分析结果不易展示。希望可以导入数据库,按照需要sql提取数据,进行展示。
对于笔者这种没有开发经验的小白来说,做这么系统是天方夜谭了。(认清现实呀)
所以必须得有现成的解决方案的,附上条件:
-
开源的,可不希望为了这个付出大代价;
-
比较流行的,对于小白来说,肯定会遇到各种问题,所以最好有各种教程,有论坛;
百度、google都可以,很容易就可以找到今天的主角,ELK,也就是
elasticsearch+logstash+kibana。
ELK是什么?
小白对于ELK的理解比较简单,大概是这样:
ELK是三个独立组件组成一套数据接收,处理(简单处理),存储,以及展示的系统。
其中的优点是:
-
完成部署后,是实时处理数据的,十分便捷;
-
听说elasticsearch可以分布式部署,运作,可用性和承载量很高;(小白啥也不知道,你说好用就好用吧)
-
部署简单,基本就解压就可以用了;
其架构大概如此:
st=>start: origin
e=>end: browser
op1=>operation: logstash处理数据后发送ES
op2=>operation: ElasticSearch
op3=>operation: kibana从ES读取数据展示
st->op1->op2->op3->e
安装ELK
系统环境
本次使用的为单台的CentOS 5.8的物理机。
Distributor ID: CentOS
Description: CentOS release 5.8 (Final)
Release: 5.8
Codename: Final
java环境
另外这套系统全部由运行在java上,所以需要java1.8的环境,具体安装不再赘述,参考这篇博文。
# java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
安装ELK
安装上文已经介绍了,非常简单,在ELASTIC官网下载,下载解压即可。
本次使用的版本是:
- elasticsearch-5.5.2
- logstash-5.5.2
- kibana-5.5.2
配置启动
logstash
logstash进行简单的配置之后,就可以直接运行了。
简单测试
按照惯例会使用最简单的std输入和std输出测试logstash能否正常工作。
./logstash-5.5.2/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
在标准输入中输入内容。比如test,会在标准输出打印先相关内容。
{
"@timestamp" => 2017-09-19T15:24:24.021Z,
"@version" => "1",
"host" => "localhost",
"message" => "test"
}
其中@timestamp字段是事件发生的时间,默认会添加。
简单配置
编辑该配置文件./logstash-5.5.2/config/logstash.conf,填入logstash的输入input{},处理filter{},输出output{}信息:
input{
#输入相关配置
}
filter{
#数据处理相关配置
}
output{
#输出相关配置
}
input{}
input{}即输入相关配置,logstash支持文件形式(file),标准输入(stdin),syslog协议(syslog),tcp(tcp)四种方式。
input还支持常见的数据格式,如json,需要使用codec插件,详细不赘述。可以查看官网学习。
filter{}
filter{}即logstash中的数据处理部分,主要有各类丰富的插件完成。这边介绍下使用的常见的几个:
grok
grok可以编码各种正则来提取所需要的信息,并且可以指定数据的格式。其基本语法为:
filter {
grok { match => { "message" => "Duration: %{NUMBER:duration}" } }
}
其中NUMBER是事先编写好的pattern,或者是自带的pattern,上例的含义为,将Duration:后符合NUMBERpattern的数据赋值给duration。
grok详细操作与介绍可以参考grok官方介绍。
date
date插件可以将日期和时间格式的数据转化成想要的格式,其中也内置很多标准的格式,其基本语法为:
filter {
date {
match => [ "logdate", "MMM dd yyyy HH:mm:ss" ]
}
}
上例的含义为,将logdate的日志格式转为MMM dd yyyy HH:mm:ss的形式。
date详细操作与介绍可以参考date官方介绍。
json
json插件可以对grokmatch到的变量进行json解格式,其基本用法为:
filter {
json {
source => "message"
}
}
上例的含义为,将source解json。
json详细操作与介绍可以参考json官方介绍。
split
split可以将某一事件按照某个字符进行拆分,比如:
filter {
split {
field => "message"
terminator => "#"
}
}
上例的含义为,将messagefield按照#进行拆分。
split详细操作与介绍可以参考split官方介绍。
其他
关于filter其他插件以及使用方法,可以查看这里。
output{}
logstash支持非常多的输出选项,输出到文件,输出到stdout,输出到端口,输出到email等,比如常见的输出到elasticsearch:
output {
elasticsearch {
hosts => ["192.168.0.2:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
flush_size => 20000
idle_flush_time => 10
sniffing => true
template_overwrite => true
}
}
elasticsearch输出参数非常多,可定制性也很强,可以从elasticsearch官方介绍 了解详细的信息。
其他形式的输出也可以从output官方介绍了解。
其他
关于logstash的其他配置和功能,可以查看其官方教程。
启动logstash
./logstash-5.5.2/bin/logstash -f ./logstash-5.5.2/conf/logstash.conf
Elasticsearch
elasticsearch经过简单配置,直接运行即可。
vi ./config/elasticsearch.yml
...
#修改cluster名称
cluster.name: test_cluster
#修改node名称
node.name: node-1
#填写IP
network.host: ***.***.***.***
#填写端口
http.port: 9200
其他配置根据需要配置。总体来说配置的内容较少。直接启动程序,测试9200是否可以正常运行。
./bin/elasticsearch
curl http://***.***.***.***:9200/
{
"name" : "node-1",
"cluster_name" : "test_cluster",
"cluster_uuid" : "lIW3ERtnQGqoXd_fPZgr6Q",
"version" : {
"number" : "5.5.2",
"build_hash" : "b2f0c09",
"build_date" : "2017-08-14T12:33:14.154Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
返回es的一些信息,表示es正常运行。
注意事项:
ES本身不允许root运行,并且对于运行有些条件。如果机器性能达不到要求,可以在./configjvm.options中调低java运行参数。
另外,如果有以下报错,请更改响应的参数。
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max number of threads [1024] for user [elk] is too low, increase to at least [2048]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
sysctl -w vm.max_map_count=262144
vim /etc/security/limits.conf
elk soft nofile 65536
elk hard nofile 65536
elk soft nproc 2048
elk hard nproc 4096
出现以下报错
system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
因为Centos6不支持SecComp,导致启动失败,详情可以看github这个issue。
解决办法是关闭下面两个选项:
vi ./config/elasticsearch.yml
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
kibana
kibana经过简单配置,直接运行即可。
vi ./config/kibana.yml
...
#配置端口
server.port: 5601
#配置host
server.host: "***.***.***.***"
#配置es查询地址
elasticsearch.url: "http://124.164.8.39:9200"
其余配置项可以保留默认值。
./bin/kibana
#curl探测成功即可。
curl -I http://124.164.8.39:5601
HTTP/1.1 200 OK
kbn-name: kibana
kbn-version: 5.5.2
cache-control: no-cache
Date: Sun, 24 Sep 2017 08:05:21 GMT
Connection: keep-alive
结语
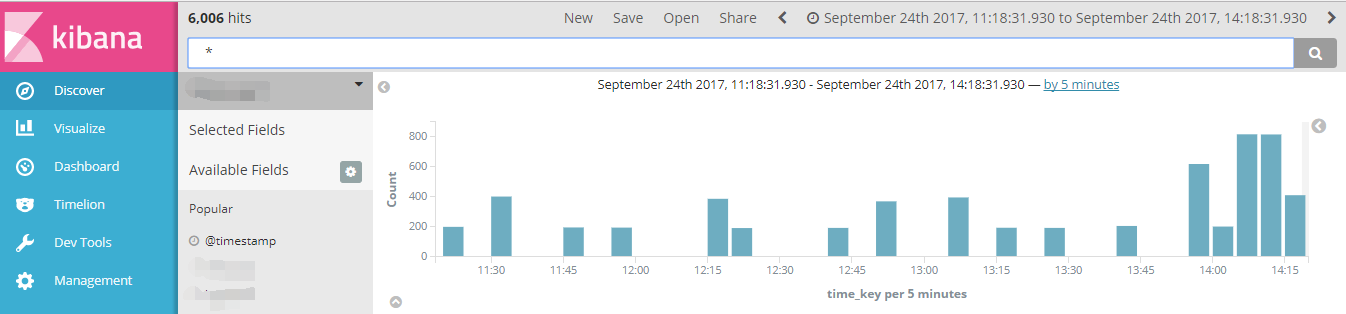
kibana界面:
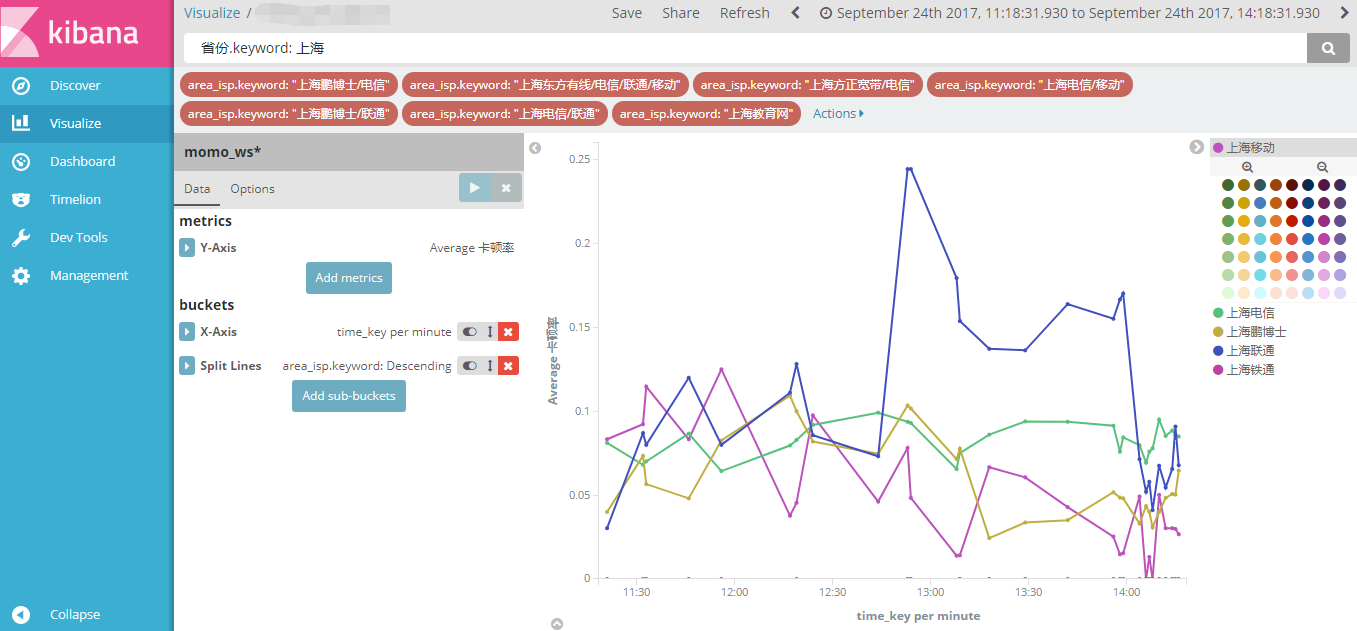
kibana绘图:
其他功能研究中~